Jacobi Decoding
在神经机器翻译(NMT)中,Transformer 模型已成为主流。然而,虽然 Transformer 在训练阶段可以高度并行化,但在推理阶段却依赖自回归解码(autoregressive decoding),即一次生成一个 token,每个新 token 又依赖前面已经生成的 token。这种顺序依赖导致推理速度成为瓶颈,特别是在需要低延迟的实际应用中。以往的研究多集中在 非自回归翻译(NAT),它可以一次性并行生成整句翻译。但 NAT 方法往往需要重新设计模型结构、消耗大量训练资源,而且翻译质量通常会有所下降。
这篇 ACL 2023 的论文提出了一条全新的路径:与其重新训练模型,不如改变解码算法本身,让现有的自回归模型也能“并行解码”。

Jacobi Decoding 就是寻求更少的迭代,寻找方程组的解(fixed point)。Jacobi decoding 在生产上,目前还没有相对自回归获得比较大的加速比。可以查考下面的流程:
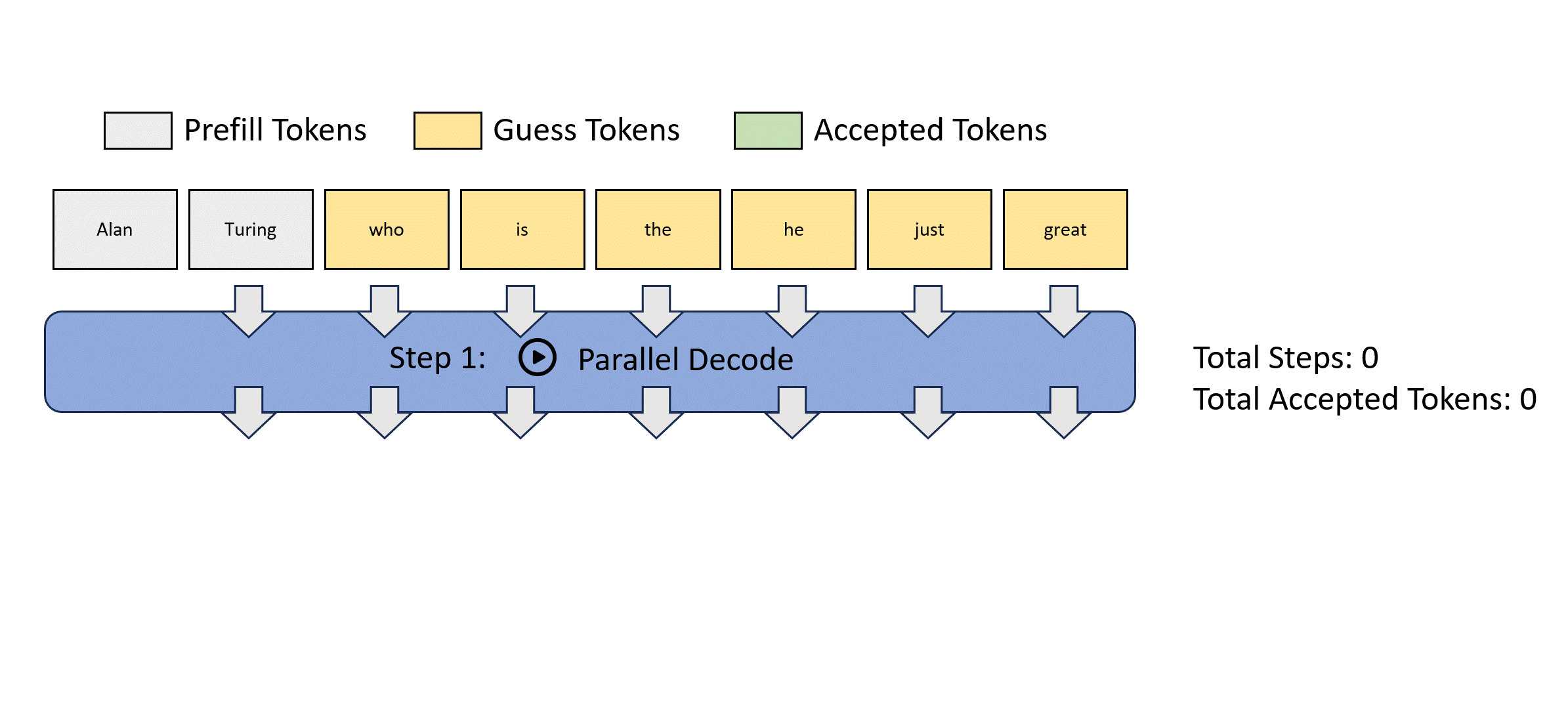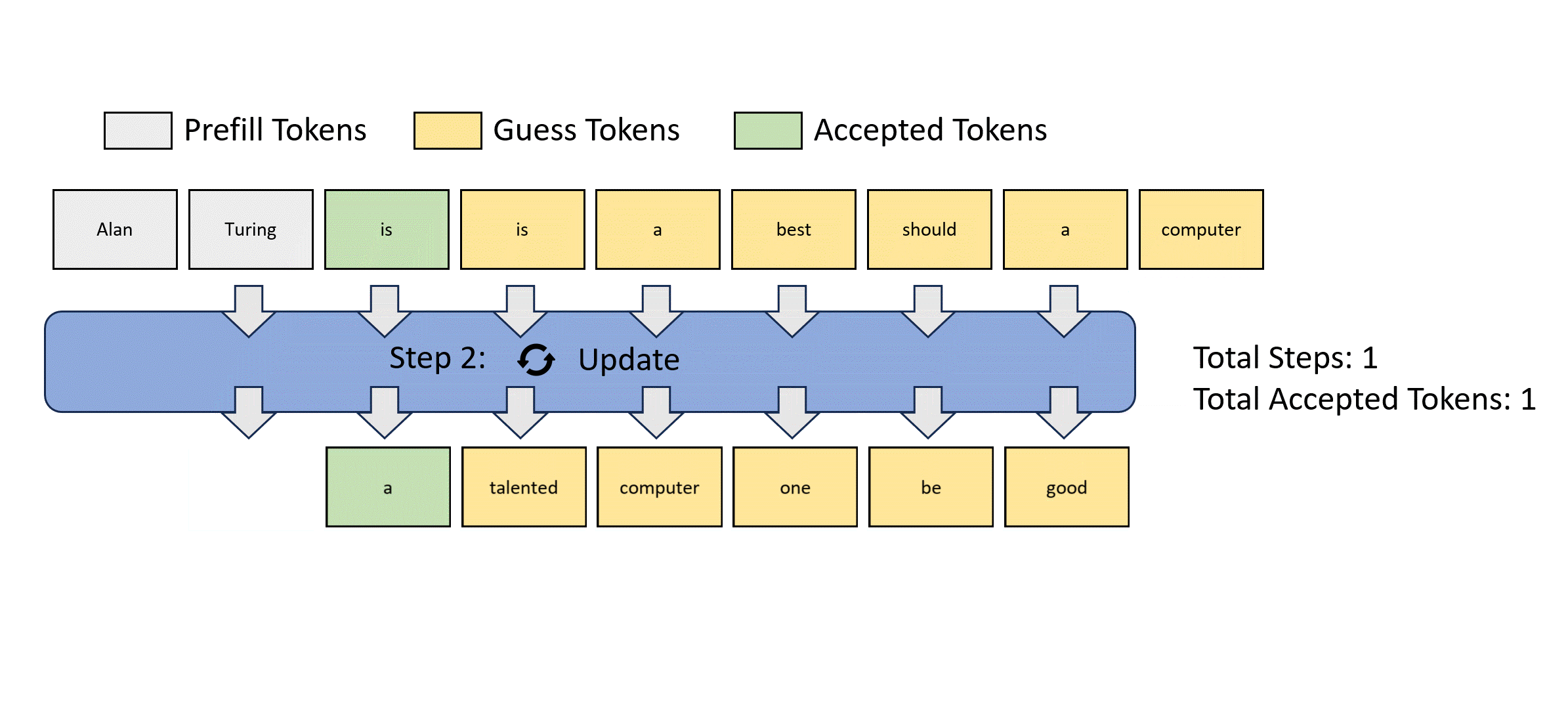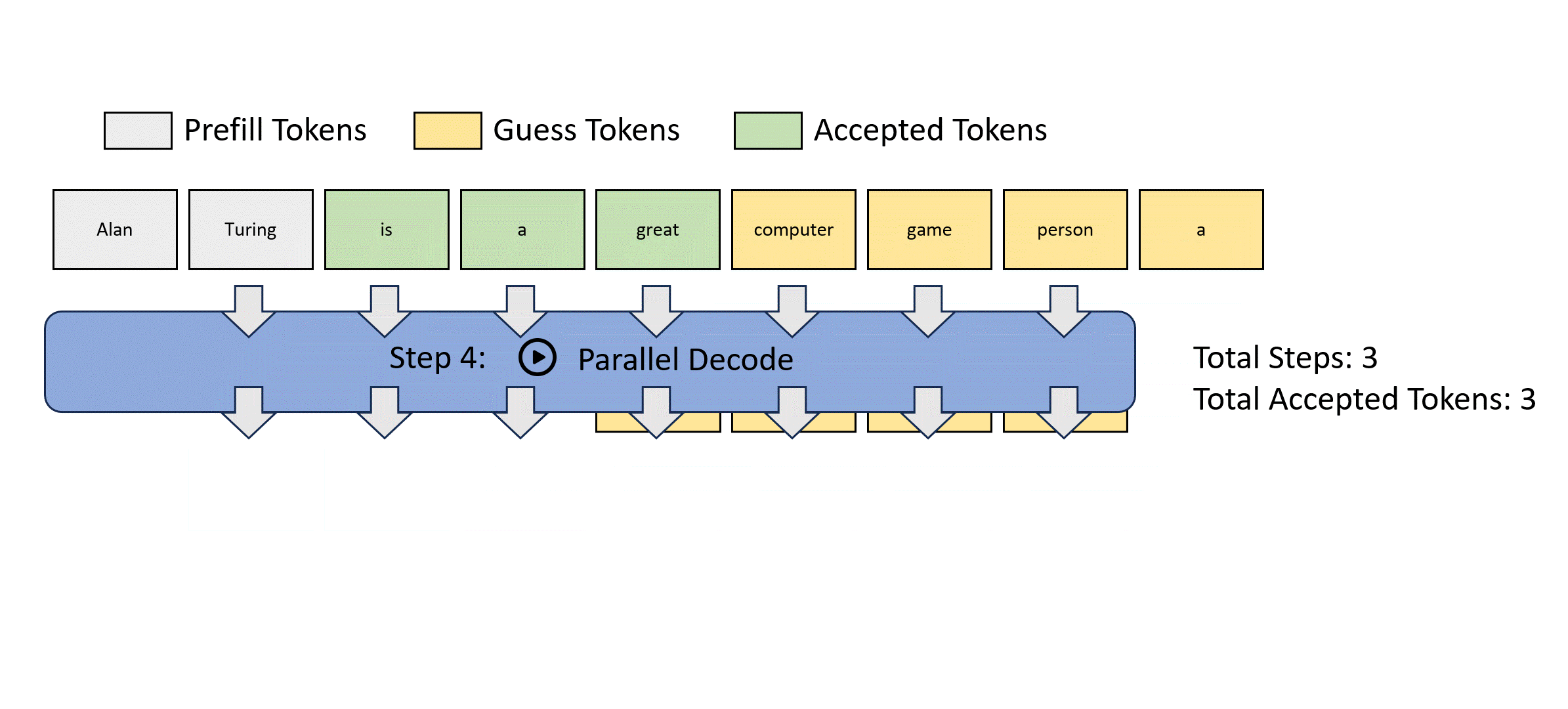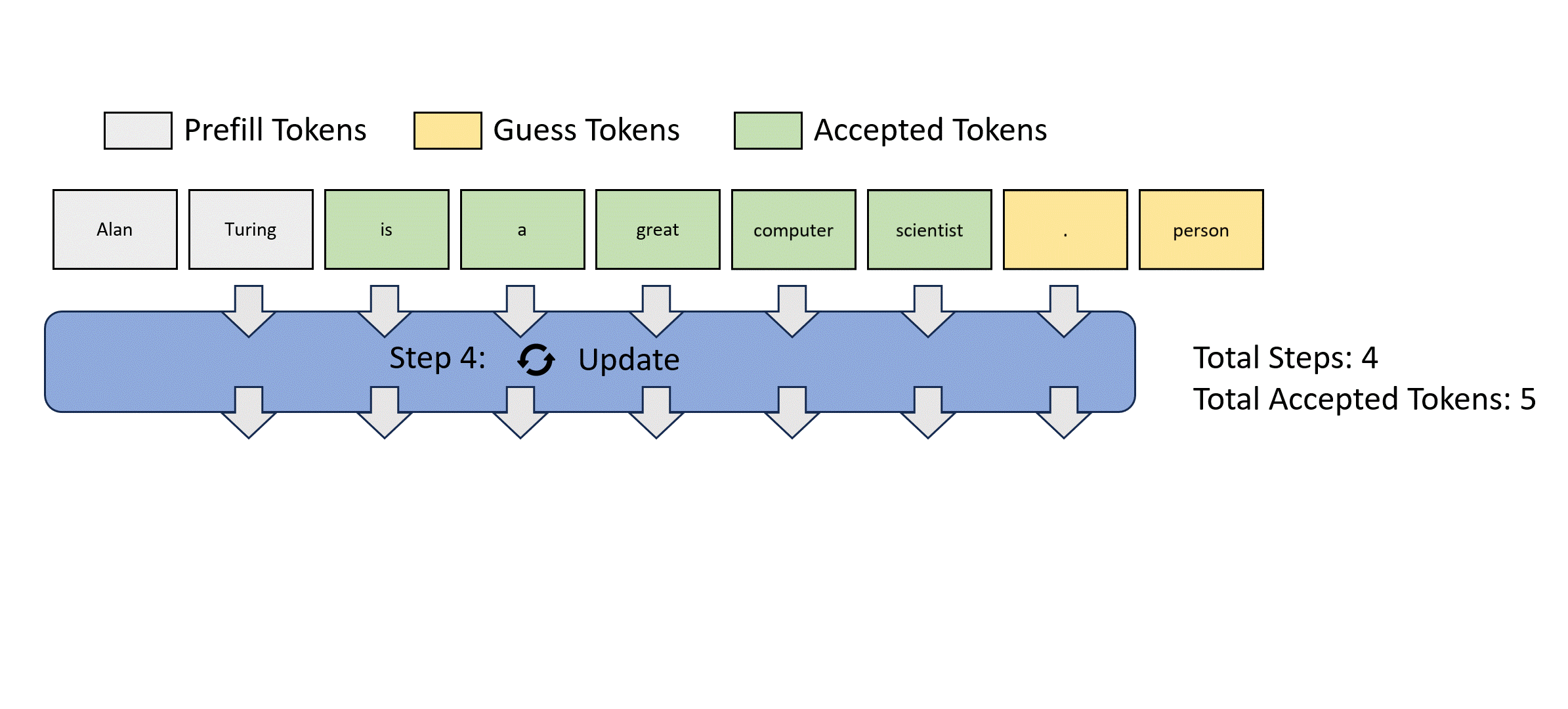
从这个图可以看到,Jacobi decoding每次迭代更新多个token,每次计算输出步长是M,可以作为一个batch并行的推理,相对单步耗时是增加的,但是对于是访存受限型的来讲,如果accept率可以上升还是又加速效果的。
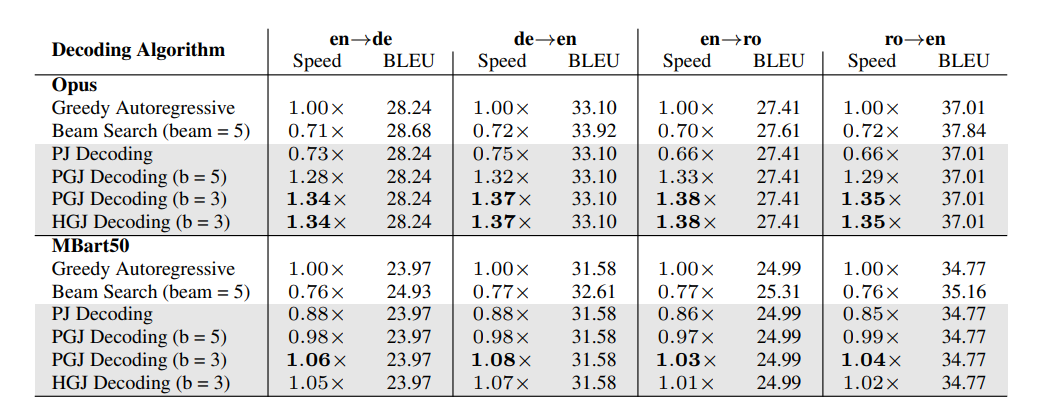
- PJ:以句子为单位,每次处理一个句子
- PGJ:以字词为单位,每次处理一个字词
- HGJ:PGJ 的基础上,增加EOS 字符中途快速退出的兼容
初始化Guess Token
如果没有特别初始化,默认Guess Token填为<pad>
class JacobiDecoder(MTDecoder):
def __init__(self, tokenizer, model, initializer, **kwargs):
super().__init__(tokenizer, model, initializer, **kwargs)
self.name = "jacobi"
self.acronym = "j"
@torch.no_grad()
def decode(
self,
input_ids,
attention_mask,
target_len=None,
gold_target=None,
init_tensor=None,
compute_ddg: bool = False,
logits_preprocessor=None,
*args,
**kwargs
):
if init_tensor is None:
init_tensor = torch.tensor(
[self.pad_token_id] * input_ids.size(0) * max_length,
device=self.device,
).reshape(input_ids.size(0), max_length)
elif self.is_mbart:
...
def initialize(self, init_transl):
if self.initializer is not None:
init_tensor, _ = self.initializer.init_translation(init_transl.shape[-1])
else:
init_tensor = None
return init_tensor
def compute_decode_kwargs(self, input_ids, attention_mask, **kwargs):
gold_autoregressive = self.generate_gold_autoregressive(input_ids, attention_mask)
init_tensor = self.initialize(init_transl=gold_autoregressive)
logits_preprocessor = self.generate_logits_preprocessor(input_ids)
return {
"init_tensor": init_tensor.clone(),
"target_len": gold_autoregressive.shape[-1],
"gold_target": gold_autoregressive,
"logits_preprocessor": logits_preprocessor
}