Jacobi 迭代把自回归的N次迭代转换为N个方程,然后联合求解。而 Jacobi Decoding 将每次迭代上一次的输出整体作为下一次的输入,其实就是把每一个 token 上的输出视作一个 2-gram,并以此作为Draft Model。论文“Break the Sequential Dependency of LLM Inference Using Lookahead Decoding”的作者想到,如果可以记录下更多的历史信息,就可以制造一个 N-gram 作为 Draft Model,这样就能提高 Speculative Decoding 的准确率。这就是Lookahead Decoding。简要来说,Lookahead=N-gram+Jacobi iteration+parallel verification,其利用 jacobi 迭代法同时提取和验证 n-grams,打破自回归解码的顺序依赖性,从而降低解码次数,实现推理加速。相比之前的并行解码,Lookahead Decoding即不需要草稿模型,也不需要像Medusa那样微调head。论文作者将 Jacobi Decoding 视为Lookahead Decoding在 2-gram 情况下的特例。

为了加速解码过程,每个Lookahead Decoding步骤被分为两个并行分支:生成n-gram的lookahead分支和验证n-gram的verification分支,两者都在一个前向传播过程中执行。
- Lookahead(前瞻)分支:这是原始雅可比解码的过程。因为不一致性的问题,此过程不会被用作主要投机验证的机制,而是作为一种采样收集或者说生成 n-gram 的并行解码过程。Lookahead 分支的目的是生成新的 N-Grams,加上其中新生成的 Token 就可以用于构建下一次 Verify 分支的候选序列。
- Verification(验证)分支:这个分支从n-gram集合中匹配的多个candidates作为投机验证输入,完成具体的投机采样过程。verification分支会选择并验证有希望的 n-gram ,并且会将其用于更新下一次 Lookahead 分支的序列。
推理

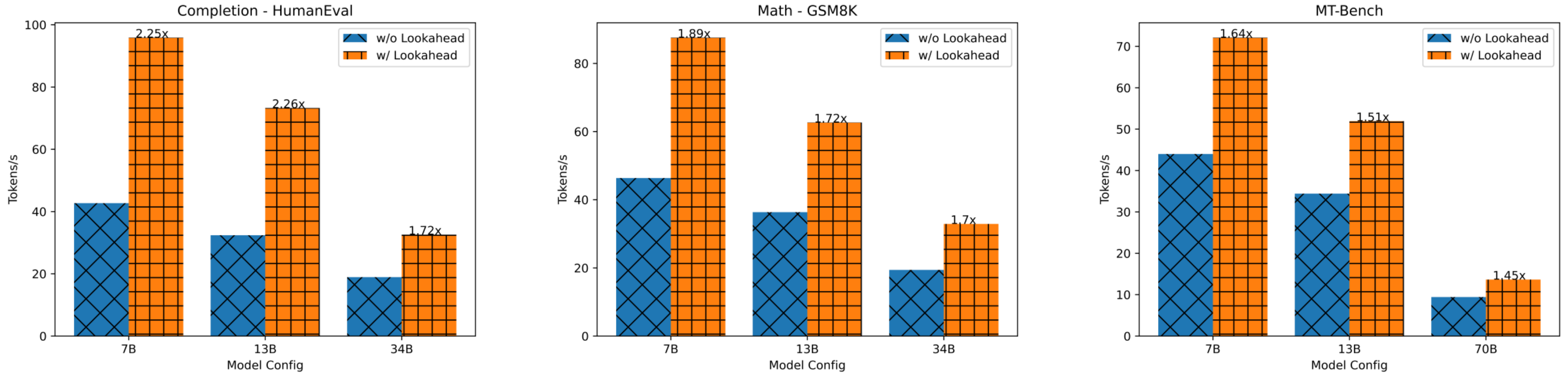
推理时,由于 LLM 解码主要受内存带宽限制,因此我们在同一步骤中合并前瞻和验证分支,利用 GPU 的并行处理能力来隐藏开销。 mask就是并行解码的关键。本示例的mask具体如上图所示。
Prepare for next iteration
当前迭代结束之后,会为下一次迭代做好准备。具体是:
- 更新 2D Window。用后一层替代前一层(最后一层由最新输出得到的logits填充),并根据被接受的 tokens 的数量截断每一层。在当前的序列中随机采样填充被截断的部分。
- 更新 n-gram。如何生成新的n-gram?其实就是就是在2d-window里面从上往下找。
- 更新下一次前向的 Attention Mask 和 KV Cache。假设接受了 k 个 tokens,就据此扩展 Attention Mask,并将这 k 个 tokens 的 cache 拼接到 KV Cache 上。
- 当满足退出条件,例如生成的 tokens 长度达到
max_length时,返回结果。