Attention: MHA, MLA, GQA,MQA

MHA
import torch
from torch import nn
from typing import Optional
def apply_rope(x: torch.Tensor, *args, **kwargs):
return x
def update_kv_cache(key_states: torch.Tensor, value_states: torch.Tensor):
return key_states.repeat(1, 1, 5, 1), value_states.repeat(1, 1, 5, 1)
class MultiHeadAttention(nn.Module):
def __init__(
self,
hidden_size: int,
num_heads: int,
head_dim: Optional[int] = None,
use_cache: Optional[bool] = False,
):
super().__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = head_dim or hidden_size // num_heads
self.scale = self.head_dim**-0.5
self.use_cache = use_cache
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim)
self.k_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim)
self.v_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size)
def forward(
self,
hidden_states: torch.Tensor,
position_ids: Optional[torch.LongTensor] = None,
):
bsz, q_len, _ = hidden_states.size()
query_states = (
self.q_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
key_states = (
self.k_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
value_states = (
self.v_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
query_states = apply_rope(query_states)
key_states = apply_rope(key_states)
if self.use_cache:
key_states, value_states = update_kv_cache(key_states, value_states)
kv_len = key_states.shape[2]
attn_weights = (
torch.einsum("bhld, bhnd -> bhln", query_states, key_states) * self.scale
)
attn_weights = attn_weights.softmax(dim=-1)
attn_weights = torch.einsum("bhln, bhnd -> bhld", attn_weights, value_states)
attn_output = self.o_proj(
attn_weights.transpose(1, 2)
.contiguous()
.view(bsz, q_len, self.num_heads * self.head_dim)
)
return attn_output
GQA (Grouped-query Attention)
import torch
from torch import nn
from typing import Optional
def apply_rope(x: torch.Tensor, *args, **kwargs):
return x
def update_kv_cache(key_states: torch.Tensor, value_states: torch.Tensor):
return key_states.repeat(1, 1, 5, 1), value_states.repeat(1, 1, 5, 1)
def repeat_kv(hidden_states: torch.Tensor, n_rep: Optional[int] = 1):
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(
batch, num_key_value_heads, n_rep, slen, head_dim
)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
class GroupQueryAttention(nn.Module):
def __init__(
self,
hidden_size: int,
num_heads: int,
num_kv_heads: int,
head_dim: Optional[int] = None,
use_cache: Optional[bool] = False,
):
super().__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.num_kv_heads = num_kv_heads
self.num_groups = num_heads // num_kv_heads
self.head_dim = head_dim or hidden_size // num_heads
self.scale = self.head_dim**-0.5
self.use_cache = use_cache
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim)
self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim)
self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size)
def forward(
self,
hidden_states: torch.Tensor,
position_ids: Optional[torch.LongTensor] = None,
):
bsz, q_len, _ = hidden_states.size()
query_states = (
self.q_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
key_states = (
self.k_proj(hidden_states)
.view(bsz, q_len, self.num_kv_heads, self.head_dim)
.transpose(1, 2)
)
value_states = (
self.v_proj(hidden_states)
.view(bsz, q_len, self.num_kv_heads, self.head_dim)
.transpose(1, 2)
)
query_states = apply_rope(query_states)
key_states = apply_rope(key_states)
if self.use_cache:
key_states, value_states = update_kv_cache(key_states, value_states)
kv_len = key_states.shape[2]
key_states = repeat_kv(key_states, self.num_groups)
value_states = repeat_kv(value_states, self.num_groups)
attn_weights = (
torch.einsum("bhld, bhnd -> bhln", query_states, key_states) * self.scale
)
attn_weights = attn_weights.softmax(dim=-1)
attn_weights = torch.einsum("bhln, bhnd -> bhld", attn_weights, value_states)
attn_output = self.o_proj(
attn_weights.transpose(1, 2)
.contiguous()
.view(bsz, q_len, self.num_heads * self.head_dim)
)
return attn_output
MLA (Multi-head Latent Attention)
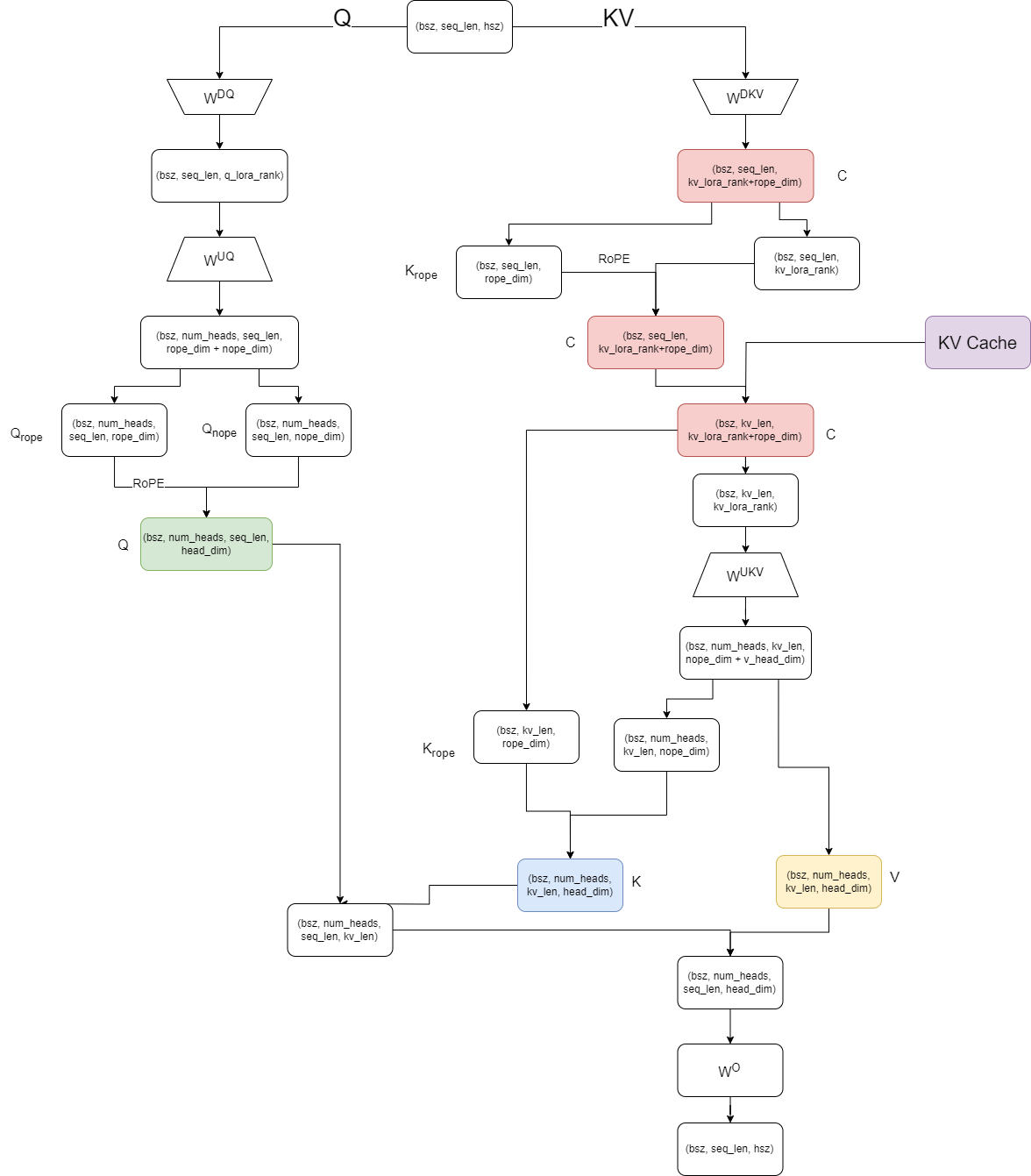
import torch
from torch import nn
from typing import Optional
def apply_rope(x: torch.Tensor, *args, **kwargs):
return x
def update_compressed_kv_cache(compressed_kv: torch.Tensor):
return compressed_kv.repeat(1, 5, 1)
def repeat_kv(hidden_states: torch.Tensor, n_rep: Optional[int] = 1):
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(
batch, num_key_value_heads, n_rep, slen, head_dim
)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
class MultiHeadLatentAttention(nn.Module):
def __init__(
self,
hidden_size: int,
num_heads: int,
q_lora_rank: int,
qk_rope_head_dim: int,
qk_nope_head_dim: int,
kv_lora_rank: int,
v_head_dim: int,
use_cache: Optional[bool] = False,
):
super().__init__()
qk_head_dim = qk_nope_head_dim + qk_rope_head_dim
self.hidden_size = hidden_size
self.num_heads = num_heads
self.q_lora_rank = q_lora_rank
self.qk_rope_head_dim = qk_rope_head_dim
self.qk_nope_head_dim = qk_nope_head_dim
self.kv_lora_rank = kv_lora_rank
self.qk_head_dim = qk_head_dim
self.v_head_dim = v_head_dim
self.scale = self.qk_head_dim**-0.5
self.use_cache = use_cache
self.q_a_proj = nn.Linear(hidden_size, q_lora_rank)
self.q_b_proj = nn.Linear(q_lora_rank, num_heads * qk_head_dim)
self.kv_a_proj = nn.Linear(hidden_size, qk_rope_head_dim + kv_lora_rank)
self.kv_b_proj = nn.Linear(
kv_lora_rank, num_heads * (qk_nope_head_dim + v_head_dim)
)
self.o_proj = nn.Linear(num_heads * v_head_dim, hidden_size)
def forward(
self,
hidden_states: torch.Tensor,
position_ids: Optional[torch.LongTensor] = None,
):
bsz, q_len, _ = hidden_states.size()
query_states = self.q_b_proj(self.q_a_proj(hidden_states))
query_states = query_states.view(
bsz, q_len, self.num_heads, self.qk_head_dim
).transpose(1, 2)
q_nope, q_rope = query_states.split(
[self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
q_rope = apply_rope(q_rope)
query_states = torch.cat([q_nope, q_rope], dim=-1)
compressed_kv = self.kv_a_proj(hidden_states)
k_rope, kv_nope = compressed_kv.split(
[self.qk_rope_head_dim, self.kv_lora_rank], dim=-1
)
k_rope = repeat_kv(k_rope.unsqueeze(1), self.num_heads)
k_rope = apply_rope(k_rope)
if self.use_cache:
compressed_kv = torch.cat([k_rope[:, 0, :, :], kv_nope], dim=-1)
compressed_kv = update_compressed_kv_cache(compressed_kv)
k_rope, kv_nope = compressed_kv.split(
[self.qk_rope_head_dim, self.kv_lora_rank], dim=-1
)
k_rope = repeat_kv(k_rope.unsqueeze(1), self.num_heads)
kv_len = compressed_kv.shape[1]
kv = (
self.kv_b_proj(kv_nope)
.view(bsz, kv_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
)
k_nope, value_states = kv.split(
[self.qk_nope_head_dim, self.v_head_dim], dim=-1
)
key_states = torch.cat([k_rope, k_nope], dim=-1)
attn_weights = (
torch.einsum("bhld, bhnd -> bhln", query_states, key_states) * self.scale
)
attn_weights = attn_weights.softmax(dim=-1)
attn_weights = torch.einsum("bhln, bhnd -> bhld", attn_weights, value_states)
attn_output = self.o_proj(
attn_weights.transpose(1, 2)
.contiguous()
.view(bsz, q_len, self.num_heads * self.v_head_dim)
)
return attn_output
MQA
import torch
from torch import nn
from typing import Optional
def apply_rope(x: torch.Tensor, *args, **kwargs):
return x
def update_kv_cache(key_states: torch.Tensor, value_states: torch.Tensor):
return key_states.repeat(1, 1, 5, 1), value_states.repeat(1, 1, 5, 1)
def repeat_kv(hidden_states: torch.Tensor, n_rep: int = 1):
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(
batch, num_key_value_heads, n_rep, slen, head_dim
)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
class MultiQueryAttention(nn.Module):
def __init__(
self,
hidden_size: int,
num_heads: int,
head_dim: Optional[int] = None,
use_cache: Optional[bool] = False,
):
super().__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_dim = head_dim or hidden_size // num_heads
self.scale = self.head_dim**-0.5
self.use_cache = use_cache
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim)
self.k_proj = nn.Linear(self.hidden_size, self.head_dim)
self.v_proj = nn.Linear(self.hidden_size, self.head_dim)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size)
def forward(
self,
hidden_states: torch.Tensor,
position_ids: Optional[torch.LongTensor] = None,
):
bsz, q_len, _ = hidden_states.size()
query_states = (
self.q_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
key_states = self.k_proj(hidden_states).unsqueeze(1)
value_states = self.v_proj(hidden_states).unsqueeze(1)
query_states = apply_rope(query_states)
key_states = apply_rope(key_states)
if self.use_cache:
key_states, value_states = update_kv_cache(key_states, value_states)
kv_len = key_states.shape[2]
key_states = repeat_kv(key_states, self.num_heads)
value_states = repeat_kv(value_states, self.num_heads)
attn_weights = (
torch.einsum("bhld, bhnd -> bhln", query_states, key_states) * self.scale
)
attn_weights = attn_weights.softmax(dim=-1)
attn_weights = torch.einsum("bhln, bhnd -> bhld", attn_weights, value_states)
attn_output = self.o_proj(
attn_weights.transpose(1, 2)
.contiguous()
.view(bsz, q_len, self.num_heads * self.head_dim)
)
return attn_output