FlashAttention
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
self-Attention
softmax
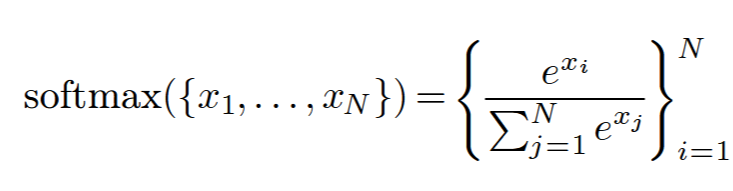
如果比较大, 可能会溢出,比如float16 最大支持65536,当x>11, 就超出了float16的表示范围。
为了解决这个问题,可以上下除以最大值,来解决溢出问题。
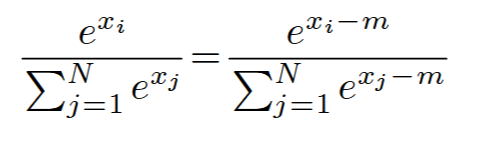
Safe softmax (3-Pass)
- 第一步 计算m 最大值
- 第二步 计算d 也就是分母,求和
- 第三步 分子/分母求每个值
需要3个循环,来访问[1,N]。
Online sofamax (2-Pass)
将第一步和第二步合成一个pass
依赖当前最大值和当前sum值
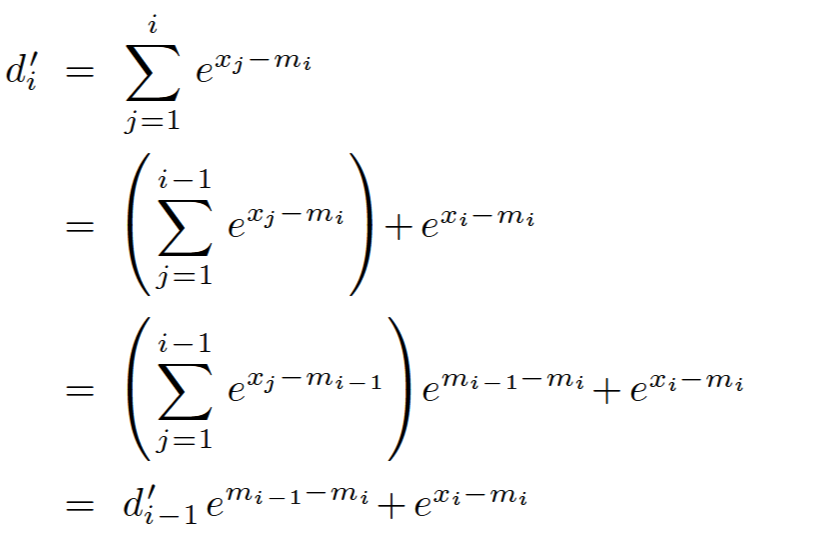

FlashAttention (1-Pass)
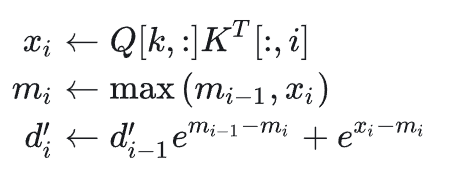
等于的行乘以的列。


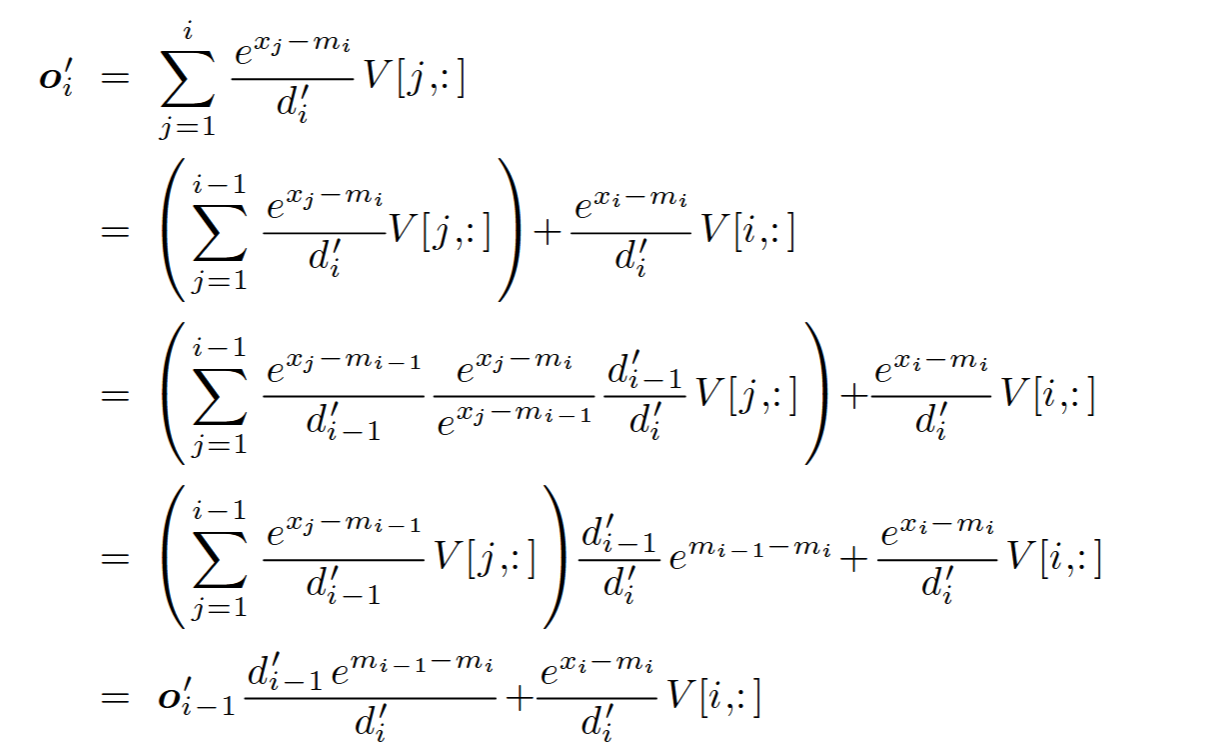
总结:
softmax 可以做成流式计算,把softmax的分母计算,也就是求和计算和求最大值计算融入到一个pass中,不依赖全局的最大值,而是局部的最大值。借助sharememory来存储中间值,这样就2pass。但是flashattention 可以。softmax之后和v相乘累加,满足加法结合率。对于MQA,GQA通过index的方法来加载KVcache计算,而不是copy一份。